

The Secret to Training Large Language Models
Web scraping is a critical skill for training large language models. Here are the basics of web scraping and how to use it to collect and store data in a structured form.

Santiago
Machine Learning. I run https://t.co/iZifcK7n47 and write @0xbnomial.

-
Web scraping is a critical skill, and yet nobody talks about it.
— Santiago (@svpino) March 22, 2023
How do you think companies are training their Large Language Models? Where do you think the data come from?
While most people worry about better prompts, here is what you need to know about building the engine: -
Web scraping allows you to get a lot of data from websites
— Santiago (@svpino) March 22, 2023
at scale.
This data is unstructured. You use web scraping to collect and store it in a structured form like CSV or JSON.
This is a critical skill that will open many doors for you. -
Here is a summary of how the process works:
— Santiago (@svpino) March 22, 2023
• Send a request to the URL you want to scrape
• Server sends the HTML back.
• Your code parses the HTML and collects the data.
Rinse and repeat for every URL you want to scrape data from. -
Libraries you can use for web scraping:
— Santiago (@svpino) March 22, 2023
• Selenium: A web testing library used to automate browser activities.
• Playwright: Another library used for testing modern web apps.
• BeautifulSoup: A library used to parse HTML documents.
But there's only one problem: -
Most people quickly find out the biggest problem with web scraping:
— Santiago (@svpino) March 22, 2023
Websites often block your IP, making it difficult to access public web data.
It quickly becomes a cat-and-mouse game and a royal waste of time.
Fortunately, there's a solution: -
I work with @bright_data. They gave me access to their new Scraping Browser API.
— Santiago (@svpino) March 22, 2023
This is a game-changer!
Their global proxy network allows you to collect data from unique IPs, making the data collection process fast, easy to manage, and scalable.
Here is one example: -
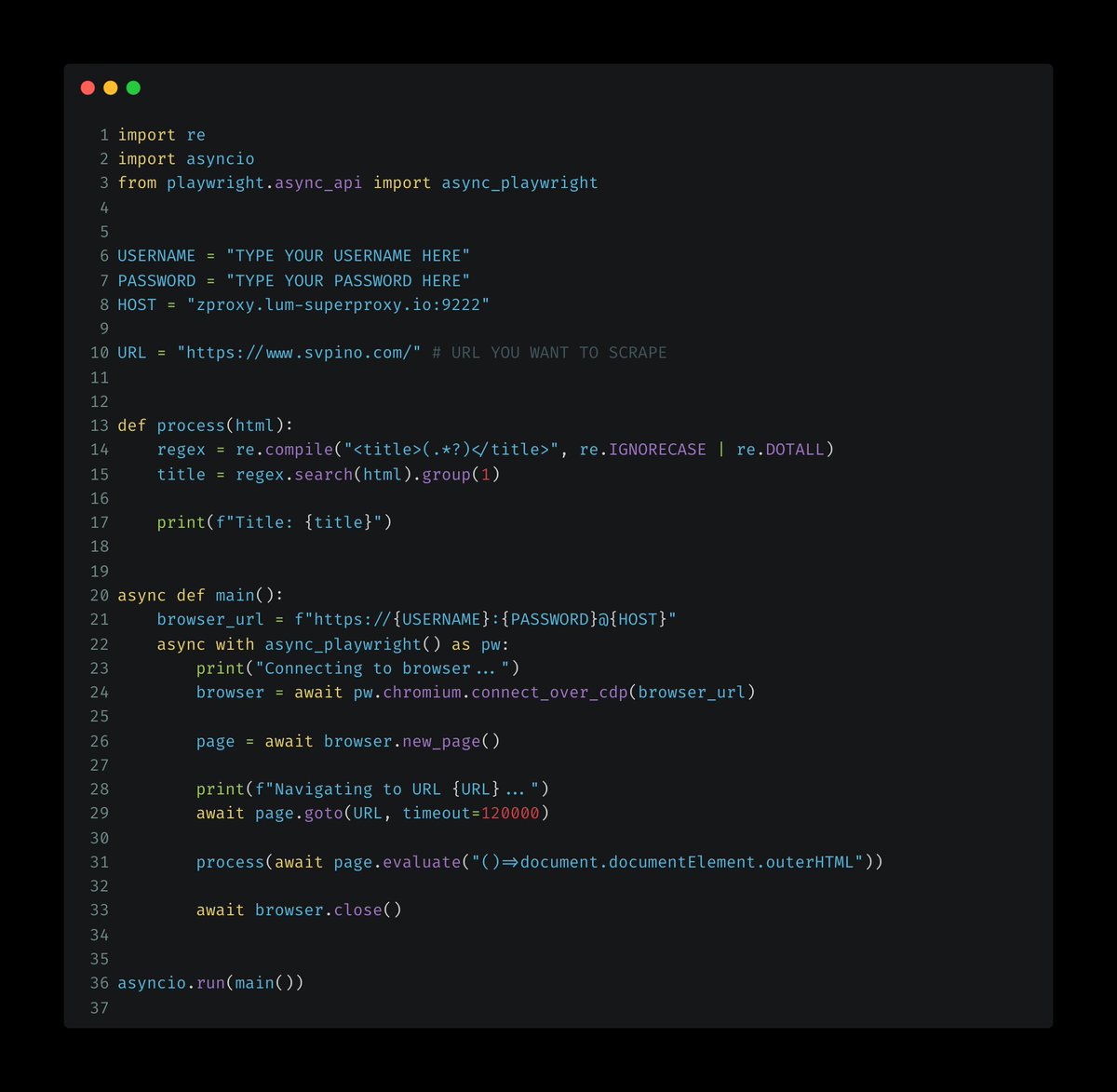
I wrote some code using Playwright and @bright_data to read the contents of my website.
— Santiago (@svpino) March 22, 2023
It uses one of @bright_data's 72M proxies to visit my site.
For the website, this will look like a unique visitor and not like a Python web scraper. pic.twitter.com/Je0b2G6FrV -
If you need structured web data, try this:
— Santiago (@svpino) March 22, 2023
1. Create an account: https://t.co/OGiIObWSCz
2. Grab your username and password, and use them here:https://t.co/kPPmTwxC17
3. Start collecting web data. It's that easy!
Thanks to @bright_data for helping me bring this to you!