

How to Train Machine Learning Models with Too Many Images
Training machine learning models with too many images can be a difficult task. This article looks at how to use better data instead of more data, as well as how real-life problems are usually the opposite of what is taught in books.

Santiago
Machine Learning. I run https://t.co/iZifcK7n47 and write @0xbnomial.

-
Real-life problems are usually the opposite of what you learn in books.
— Santiago (@svpino) June 13, 2023
Toy datasets are always small, but many companies deal with a lot of data, and most engineers have no clue what to do with that.
Here is one of the most exciting developments in the field: -
One of the biggest problems in the industry is how to train machine learning models when you have too many images.
— Santiago (@svpino) June 13, 2023
And you can't just use all of them:
• Too much time
• Too much money
If you want to get a raise, you need to figure out how to use better data, not more of it. -
Despite what you learned in school, the solution is not to take a random portion of the images to train your model.
— Santiago (@svpino) June 13, 2023
There's a better way:
Using embeddings, we can compare visual similarities between images and build a better dataset.
Here is one example: -
The team @superb_hq ran an experiment using the LOCO dataset:
— Santiago (@svpino) June 13, 2023
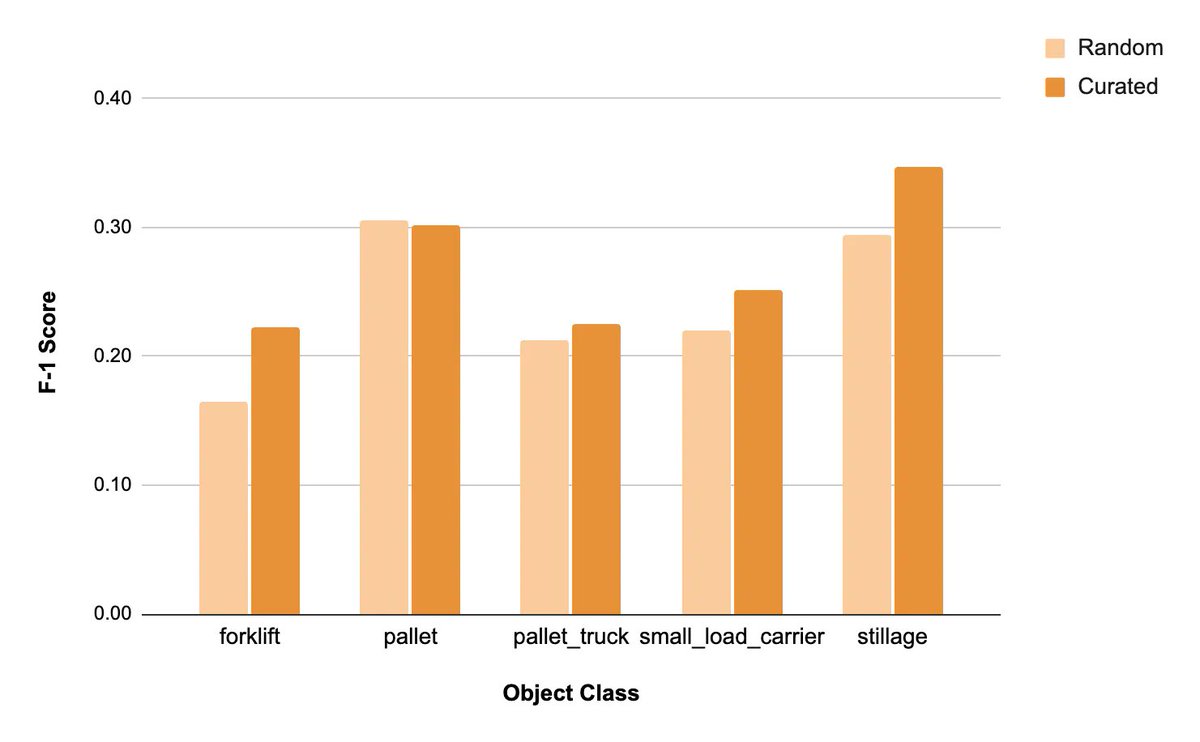
They trained a model using 1,000 random samples and compared it with a model trained on 1,000 curated samples.
The F1-Score of the latter was 14.5% better on average across classes! pic.twitter.com/nouJLJHZuP -
Here is a comparison between the random and the curated data.
— Santiago (@svpino) June 13, 2023
Notice how the random data has a similar distribution to the overall dataset, but the curated data looks very different:
• It undersamples the majority classes
• It oversamples the minority classes pic.twitter.com/rYIDpSiLLG -
These results are very exciting!
— Santiago (@svpino) June 13, 2023
No manual work is involved: we can curate the data automatically.
The tool clusters the embeddings and finds the best samples to build a dataset.
Here is more information: https://t.co/E5pWUr3Sfa